


Wiring up a database in the API service
Setting up Postgres, SQL builders, and migrations, step by step


Today I'll talk about how I set up the database for the API server of reread.to. It was a bit of a hassle and there were tons of things I didn't know. However, I think I've figured out the basics now and I'll tell you how I did it. In this article, I’ll discuss how to set up your Go API service to connect to Postgres, use a sql builder, and setup migrations.
But first, a bit of a notice. In my previous article I mentioned that I'll set up a landing page and do some marketing stuff. I didn't do it. No good reason, but each time I tried to do it a wave of procrastination would come over me and I would put it off. That's also why this article is coming out after a lengthy break. There are various lessons to be learnt here, but the big one for me is to not talk about the next article from now on. I don't want the pressure.
Another notice, when I first started out, I decided to post daily, but since I have a day job, two kids, and a meagre social life, this quickly became difficult. I have to make enough progress on reread and write about it. So, I’ve decided to post weekly (or bi-weekly if I decide to write something unrelated to reread). 👆 There’s a email form up there that’ll notify you when there’s a new post if you sign up.
Now, back to go and databases and all the good stuff. It's a bit embarrassing to say as a so-called backend engineer, but I'm not the best with databases. I know about them, I can build a decent schema sometimes, and I know how to use them well sometimes, but they always make me nervous. If you see things that make you cringe, please let me know. I'd love to learn to be a better database person.
Decisions, decisions
Starting off, the database I’m using for reread is Postgres, as I’ve mentioned earlier. It's a super popular choice, so I'm not getting any points for taking the road less travelled (nor am I interested in that kinda thing, and neither should you, just sayin’). It also happens to be the database I've come across most in my recent jobs, so I'm a bit more familiar with it than other popular relational databases.
I think it’s also useful to call out nosql databases too while we’re here. Overall, I prefer nosql databases over sql ones, as they just fit in my head better. However, I think at times they’re also just as much of a pain to deal with. For reread, relational made sense because I’ll be doing a lot of connections between various links and sharing etc, so I went with that.
Now that we have decided on a database, I thought about how to interact with it. Here’s where things got a bit confusing again, because I am not very knowledgeable about Go, and went into research mode. This took up a lot more time than I’d have liked, and at some point I decided to just pick one.
A thing to note is that I decided not to use ORMs. But I ❤️ ORMs, so why? I’ve always used them because of all the reasons I mentioned earlier — the fact that I’m not too comfortable with databases — and ORMs extract all that away from me. However, in the middle of my side projects, I’ve always found them to be a bit constraining and require learning a whole new API just to talk to the database. I'm not saying this they're un-usable, just inconvenient. This time, I decided I didn’t want to do that. I also dislike writing multi-line strings of sql within my code. Thus, a nice middle-ground was needed. I was looking for a ‘sql builder’. For that I found goqu. I don’t know enough about it yet to recommend it, but I’ll continue talking about this as I proceed with the series.
Now, sql builders are nice and all, but to work with production databases, there’s another piece that I think is even more important: migration. As I continue to develop reread, I’ll realize I need to update the database schema. Either I made a mistake, or I need to store more information, or optimize how data is stored so I can speed up APIs that are taking too long due to my janky sql understanding. For migrations, Go seems to have a de-facto library, aptly called migrate.
Integrating with other software is seldom simple. Now that I have decided on a database, sql writing and migration libraries, there are still more things to learn. For one, there’s a standard library in Go that provides a standard interface for dealing with sql databases, called sql. This is really nice, because all the databases-specific drivers in Go work with this high-level interface. The driver being the library that knows how to communicate with a specific kind of database. This means that as a developer all I need to do is learn how to use the sql interface, and install the driver of the database.
Did I mention that integrating with other software is seldom simple? Because while the sql interface is a great idea, it’s a bit too low-level. Hence the need for libraries like goqu. Additionally, the default driver for Postgres, called pq is great, but my internet wanderings told me pgx might be a better option. When in doubt, I follow the shinier library (which has rarely worked out for me, alas). Now, the trouble is that pgx isn’t fully compatible with the sql library because it exposes some Postgres specific features, of course. Still, that’s not a deal breaker yet.
Setting up a development database
The easiest way to run a Postgres database on your machine is via Docker. I add another service to the docker-compose.dev.yml file and it's all good to go. I explained the setup in an earlier post. The section for the database service looks like:
redb:
image: postgres:14.2-alpine
environment:
POSTGRES_USER: reread
POSTGRES_PASSWORD: Q#]4-Dyf2kU
POSTGRES_DB: reread
ports:
- '5432:5432'
volumes:
- ./data/postgres/:/var/lib/postgresql/data
networks:
- rereadnet
Now when run make up (which runs docker-compose up internally), it will now bring up reread's Go API service and the Postgres database. Because I now have two services talking to each other, I've taken a step to create a docker bridge network. The configuration of that's pretty simple:
networks:
rereadnet:
driver: bridge
I just add the network section to both services and docker-compose will let them talk to each other without any complaints.
In order to connect to this new database, the database url looks something like so:
postgresql://reread:Q%23%5D4-Dyf2kU@redb:5432/reread
It follows the format:
scheme://username:password@hostname:port/databaseName
Passwords and URL Encoding
You might notice that the password in the actual url looks different from what I specified in the docker-compose configuration. That's because I had to url encode it. You can just run the following javascript in your browser (or if you have node installed):
encodeURIComponent("Q#]4-Dyf2kU") // > Q%2523%255D4-Dyf2kU
Connecting to the database
Now that I have a database and a URL to connect to, it's time to update the API service. For that, I created a new Go package called database that will contain all the code for setting up the database connection. Here’s the connection logic:
var sqlDb *sql.DB
func getSqlDb() (*sql.DB, error) {
if sqlDb != nil {
return sqlDb, nil
}
logger := util.GetLogger()
config := config.GetConfig()
if config == nil {
logger.Error("unable to get config at db start")
return nil, errors.New("no config found")
}
baseDb, err := sql.Open("pgx", config.DatabaseUrl)
if err != nil {
logger.Error("unable to connect to db: ", err)
return nil, err
}
if err := baseDb.Ping(); err != nil {
logger.Error("unable to connect to database: ", err)
return nil, err
}
return baseDb, nil
}
The above code is doing the following things:
- Getting the application config to obtain the database url.
- Creating a new database connection object using the driver
pgxand, - Connecting to the database
Since I'm still using the Go sql library here, the code doesn't change much even if a different driver is being used. With this, I was able to confirm whether I was able to connect to the database, and moved on to adding my first table through migrations.
Migrations
Migrations are mutations to the database schema that are applied sequentially. Each migration consists of two parts, an 'up' part and a 'down' part. The up migration is usually the important part of the migration as it contains changes to the schema moving forward. The down migration contains sql to revert the changes made by the up migration. This is incase of rollbacks and errors.
The thing I like about developing the API service in Go is that it compiles to a single binary, and while that's not a huge deal, I think there's a bit of beauty to it. To prevent that from changing, I wanted to see if we can include all the migrations within the Go binary that's built. Migrate - the versatile tool that it is - allows for a variety of 'sources' like the file system, Github remote repositories, AWS S3, and even a curiously named source called 'Go-Bindata'. The latter is the most interesting one for me.
Go-Bindata is a library and a CLI tool that converts any file to be usable within Go. This is relevant for migration because it can take the migration sql files and convert them into a single Go package. That package can be included within the API service which can be accessed without reading from the filesystem.
Both migrate and Go-Bindata have CLI tools and since I'm on MacOS, I'll use homebrew to install them. As mentioned earlier, I use a dependency updating script, and thus I add the two installs within.
With the two installs completed, I create a folder called migrations within my database folder and within I run the migrate command to create my very first migration:
migrate -database ${DATABASE_URL} create -ext sql -dir database/migrations init-schema
This creates two empty files for me:
20220318050730_init-schema.down.sql
20220318050730_init-schema.up.sql
In the up migration, I'll add in a basic User table:
CREATE TABLE users (
id serial PRIMARY KEY,
username varchar(50) UNIQUE NOT NULL,
fullname varchar,
email varchar UNIQUE NOT NULL,
google_token varchar,
created_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL
);
and in the down migration, I'll remove the user table:
DROP TABLE IF EXISTS users;
I forgot to mention, there's an easy way out of all this, and that's to use migrate to actually migrate the database. Each time I'll deploy, I can just hop on to the server, and run:
migrate -database ${DATABASE_URL} -source file://database/migrations up
However, this isn't a viable solution for multiple reasons. Mainly, this way the API service will never reliably have a database schema it expects, because I'll either migrate it before the service has deployed, or after. Neither is a great option. So, onwards to Go-Bindata and migrating as part of the service startup sequence. First, I'll ask Go-bindata to create the Go file for loading migrations:
update-migrations:
cd ./database/migrations && go-bindata -pkg migrations .
This is an excerpt from my Makefile. The important part is this:
go-bindata -pkg migrations .
This invokes go-bindata and tells it to create a Go package called migrations and include all the files in the datbase/migrations directory. This spits out a file called bindata.go. I can rename the file to be named differently by passing in an additional argument -o my-special-name.go but I like the clarity of bindata.go so I'll keep it.
With this file created, it's time to migrate the database. The code for migration looks like this:
func migrateDb() error {
logger := util.GetLogger()
db, err := getSqlDb()
if err != nil {
return err
}
s := bindata.Resource(migrations.AssetNames(),
func(name string) ([]byte, error) {
return migrations.Asset(name)
})
binData, err := bindata.WithInstance(s)
if err != nil {
logger.Error("unable to read migrations: ", err)
return err
}
dbMigrationDriver, err := pgxMigrate.WithInstance(db, &pgxMigrate.Config{})
if err != nil {
logger.Error("unable to create db driver for migrate: ", err)
return err
}
m, err := migrate.NewWithInstance("go-bindata", binData, "pgx", dbMigrationDriver)
if err != nil {
logger.Error("unable to setup migrations: ", err)
return err
}
err = m.Up()
if err != nil {
if err == migrate.ErrNoChange {
logger.Info("no migrations required")
} else {
logger.Error("unable to migrate: ", err)
return err
}
}
return nil
}
This is a bit chunky, but I'll break the code down a bit to make it more understandable.
First: Let's get me some database:
db, err := getSqlDb()
I'm calling the function I wrote above to get a new connection to the database. With the database created, it's time to migrate. It still has a few steps. As I said earlier, the migration tool is versatile and can work with multiple 'sources' (like go-bindata) and multiple databases (like Postgres), so we have to connect both of these things manually. The first step is the 'source':
s := bindata.Resource(migrations.AssetNames(),
func(name string) ([]byte, error) {
return migrations.Asset(name)
})
binData, err := bindata.WithInstance(s)
// ...
This uses migrate's bindata integration (bindata.Resource) and uses the generated package migrations to create a source for migrate to read. This is a bit confusing because all the names sound alike, but essentially it's just telling migrate how to read the migrations.
Next up, I need to tell migrate about the 'database':
dbMigrationDriver, err := pgxMigrate.WithInstance(db, &pgxMigrate.Config{})
// ...
Finally, I create a migrate instance with the previously created 'source' and 'database':
m, err := migrate.NewWithInstance("go-bindata", binData, "pgx", dbMigrationDriver)
and to migrate the database to latest, we need to call Up:
err = m.Up()
if err != nil {
if err == migrate.ErrNoChange {
logger.Info("no migrations required")
} else {
logger.Error("unable to migrate: ", err)
return err
}
}
The reason why I added the error handling here is to talk about a gotcha I saw. If migrate doesn't need to do any migrations when I call Up, it will throw with an error called ErrNoChange. Since, that's not really an error, I need to handle that separately as a success and move on.
If I now restart the service, I'll see that the migrations are all done.

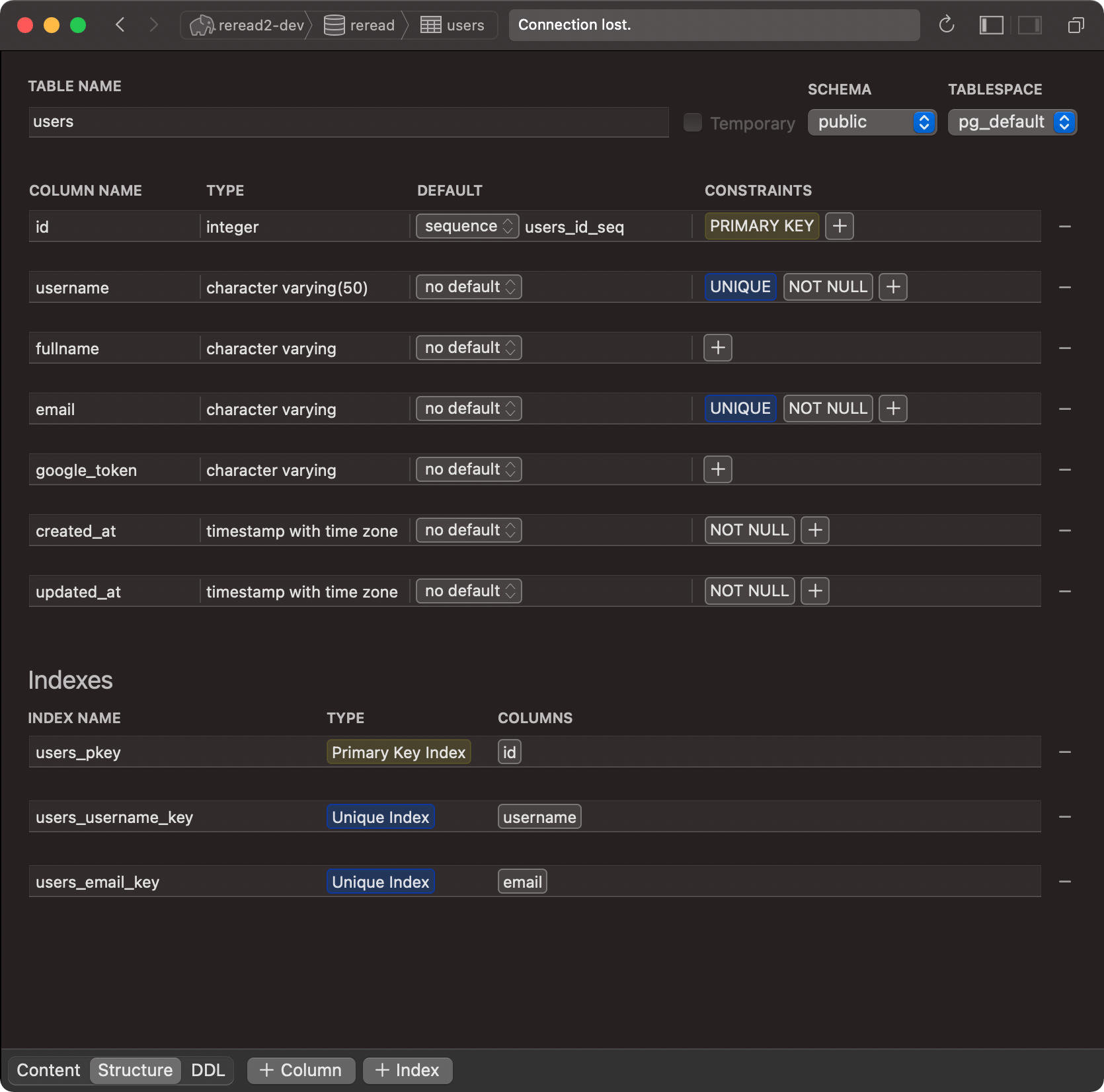
One last thing to do is to create the SQL builder instance. That looks like so:
var db *goqu.Database
func GetDb() (*goqu.Database, error) {
if db != nil {
return db, nil
}
err := migrateDb()
if err != nil {
return nil, err
}
baseDb, err := getSqlDb()
if err != nil {
return nil, err
}
logger := util.GetLogger()
db = goqu.New("postgres", baseDb)
db.Logger(InitDbLogger(logger))
return db, nil
}
This is the function I'll be using the most to talk to the database, and it makes sure I don't re-initialize the database connection and do migrations when not needed. It also connects a logger so I can start seeing what the builder is doing.
Phew, that was a long one, and even with all of that, I really haven't used the database at all yet. I'll address using the database as I start to build features in future articles.